タグ: tutorial
回路が大きくなると、ゲート列のコピー&ペーストを避けたくなります。Qamomileは2つの再利用メカニズムを提供しています:
ヘルパーQKernel — ある
@qkernelを別の@qkernelから呼び出す、通常の関数合成と同じ方法です。@composite_gate— 量子カーネルをカスタム可能な名前付きゲートに昇格させ、図中で単一のボックスとして表示します。
さらにトップダウン設計のための第3のパターンもあります:
スタブゲート — 実装本体を持たないゲートで、リソース推定に使います。例えば、グローバー探索アルゴリズムを設計しており、オラクルが約40個のTゲートを使用することはわかっているが、まだ実装していないとします。スタブゲートを使用すると、完全なオラクル実装なしでアルゴリズムの総コストを推定できます。
# 最新のQamomileをpipからインストールします!
# !pip install qamomileimport qamomile.circuit as qmc
from qamomile.circuit.ir.operation.composite_gate import ResourceMetadata
from qamomile.qiskit import QiskitTranspiler
transpiler = QiskitTranspiler()パターン1:ヘルパーQKernel¶
どの@qkernel関数も別の@qkernelから呼び出せます。トランスパイル時にインライン展開されるため、トランスパイル結果はフラットな回路になります。
@qmc.qkernel
def entangle_once(q0: qmc.Qubit, q1: qmc.Qubit) -> tuple[qmc.Qubit, qmc.Qubit]:
q0, q1 = qmc.cx(q0, q1)
return q0, q1
@qmc.qkernel
def ghz_with_helper(n: qmc.UInt) -> qmc.Vector[qmc.Bit]:
q = qmc.qubit_array(n, name="q")
q[0] = qmc.h(q[0])
for i in qmc.range(n - 1):
q[i], q[i + 1] = entangle_once(q[i], q[i + 1])
return qmc.measure(q)ghz_with_helper.draw(n=4, fold_loops=False)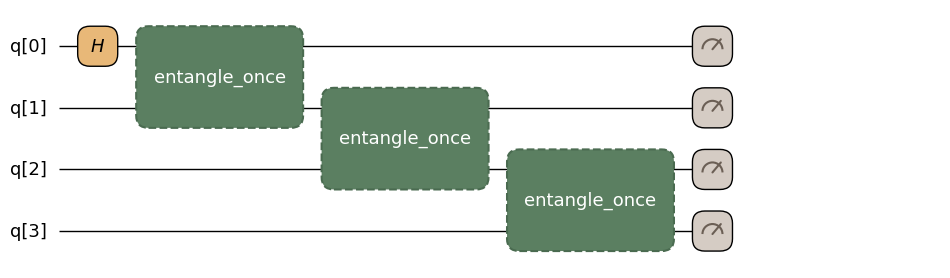
result = (
transpiler.transpile(ghz_with_helper, bindings={"n": 4})
.sample(
transpiler.executor(),
shots=128,
)
.result()
)
print("GHZ result:", result.results)
assert result.shots == 128
assert sum(count for _, count in result.results) == 128
# 4 量子ビット GHZ 状態 → (0, 0, 0, 0) と (1, 1, 1, 1) のみ出現。
assert all(
outcome in {(0, 0, 0, 0), (1, 1, 1, 1)}
for outcome, _ in result.results
)GHZ result: [((0, 0, 0, 0), 52), ((1, 1, 1, 1), 76)]
ヘルパーentangle_onceにより、呼び出し側のコードが読みやすくなります。トランスパイル後の回路ではインライン展開されるため、サブブロックではなく個々のCXゲートが見えます。
qc = transpiler.to_circuit(ghz_with_helper, bindings={"n": 4})
print(qc.draw()) ┌───┐ ┌─┐
q_0: ┤ H ├──■───────┤M├──────────────
└───┘┌─┴─┐ └╥┘ ┌─┐
q_1: ─────┤ X ├──■───╫──────┤M├──────
└───┘┌─┴─┐ ║ └╥┘┌─┐
q_2: ──────────┤ X ├─╫───■───╫─┤M├───
└───┘ ║ ┌─┴─┐ ║ └╥┘┌─┐
q_3: ────────────────╫─┤ X ├─╫──╫─┤M├
║ └───┘ ║ ║ └╥┘
c: 4/════════════════╩═══════╩══╩══╩═
0 1 2 3
ヘルパーへのスカラーリテラルの受け渡し¶
ヘルパーqkernelがスカラー型(UInt,Float,Bit)のパラメータを宣言している場合、呼び出し側ではPythonの生のリテラルをそのまま渡せます。QamomileがintをUInt、floatをFloat、boolをBitに自動昇格します。helper(q, 0, 0.5)はhelper(q, qmc.uint(0), qmc.float_(0.5))と等価です。明示的なqmc.uint/qmc.float_/qmc.bitコンストラクタは、値に名前を付けたい場合や複数の呼び出し箇所で共有したい場合にのみ使えば十分です。
@qmc.qkernel
def rotate_first(
q: qmc.Vector[qmc.Qubit],
idx: qmc.UInt,
angle: qmc.Float,
) -> qmc.Vector[qmc.Qubit]:
q[idx] = qmc.ry(q[idx], angle)
return q
@qmc.qkernel
def helper_with_literals(n: qmc.UInt) -> qmc.Vector[qmc.Bit]:
q = qmc.qubit_array(n, name="q")
# int / float リテラルは runtime で ``qmc.UInt`` / ``qmc.Float`` に
# auto-promote されるが、kernel の静的シグネチャは Qamomile ハンドル型を
# そのまま要求する。下の ignore はその意図的なギャップを明示するもの。
q = rotate_first(q, 0, 0.5) # type: ignore[arg-type]
return qmc.measure(q)
helper_with_literals.draw(n=3, fold_loops=False, inline=True)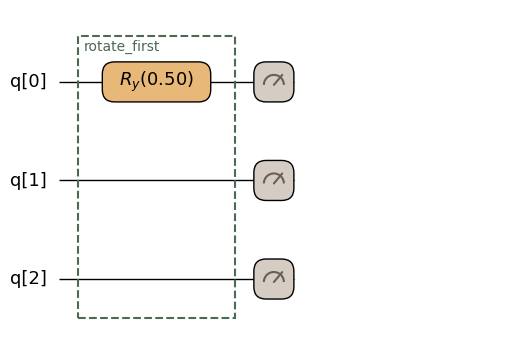
パターン2:@composite_gate¶
再利用可能なブロックを回路図で名前付きボックスとして表示したい場合@composite_gateでを使うこともできます。また、より高度な内容としてコンポジットゲートにすることで複数の実装方式を与えるといったカスタム設定を与えることも可能です。
@qkernelの上に@composite_gate(name="...")を重ねて書きます:
@qmc.composite_gate(name="entangle")
@qmc.qkernel
def entangle_link(q0: qmc.Qubit, q1: qmc.Qubit) -> tuple[qmc.Qubit, qmc.Qubit]:
q0, q1 = qmc.cx(q0, q1)
return q0, q1
@qmc.qkernel
def ghz_with_composite(n: qmc.UInt) -> qmc.Vector[qmc.Bit]:
q = qmc.qubit_array(n, name="q")
q[0] = qmc.h(q[0])
for i in qmc.range(n - 1):
q[i], q[i + 1] = entangle_link(q[i], q[i + 1])
return qmc.measure(q)ghz_with_composite.draw(n=4, fold_loops=False)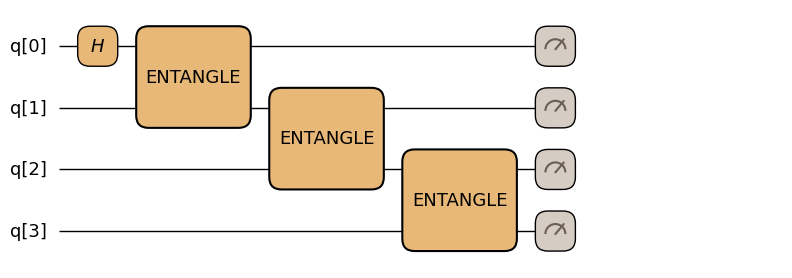
どちらを使うべきか?¶
| パターン | draw()での表示 | 使用場面 |
|---|---|---|
ヘルパー@qkernel | インライン展開(フラット) | コードの整理 |
@composite_gate | 名前付きボックス | ドメインレベルの抽象化/高度なカスタム |
パターン3:トップダウン設計のためのスタブゲート¶
オラクルなどを想定する量子アルゴリズムを設計する場合に内部は未知のまま回路を組みたいこともあると思います。スタブゲートは実装本体を持たず、名前・量子ビット数・オプションのリソースメタデータだけを持ちます。
オラクルあるいはサブルーチンが開発中でも、アルゴリズム全体のコストを推定できます。
スタブゲートを使うためには@composite_gateの引数としてstub=Trueを指定します。このとき同時にリソース情報をResrouceMetadataとして与えられます。
@qmc.composite_gate(
stub=True,
name="oracle",
num_qubits=3,
resource_metadata=ResourceMetadata(
query_complexity=1,
t_gates=40,
),
)
def oracle_box():
pass
@qmc.qkernel
def algorithm_skeleton() -> qmc.Vector[qmc.Qubit]:
q = qmc.qubit_array(3, name="q")
q = qmc.h(q)
q[0], q[1], q[2] = oracle_box(q[0], q[1], q[2])
return qalgorithm_skeleton.draw(fold_loops=False)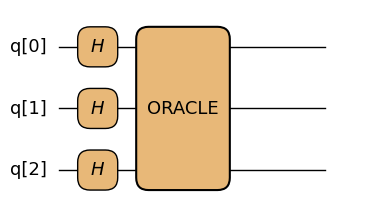
スタブゲートを含むqkernelのリソース推定¶
estimate_resources()は、オラクル内部が未実装でもqkernel全体を解析できます。既知の回路部分は通常どおり集計され、未知のスタブ部分はest.gates.oracle_calls / est.gates.oracle_queriesとして追跡されます。
est = algorithm_skeleton.estimate_resources().simplify()
print("qubits:", est.qubits)
assert est.qubits == 3
print("total gates:", est.gates.total)
# H ゲート 3 個(qubit_array(3) へのブロードキャスト); stub の `oracle_box`
# は gates.total ではなく gates.oracle_calls にカウントされる。
assert est.gates.total == 3qubits: 3
total gates: 3
次に、通常ゲートと複数スタブオラクルを混在させたqkernelで確認します。
@qmc.composite_gate(
stub=True,
name="oracle",
num_qubits=3,
resource_metadata=ResourceMetadata(query_complexity=2),
)
def phase_oracle():
pass
@qmc.composite_gate(
stub=True,
name="mixing",
num_qubits=3,
resource_metadata=ResourceMetadata(query_complexity=1),
)
def mixing_oracle():
pass
@qmc.qkernel
def iterative_oracle_skeleton(rounds: qmc.UInt) -> qmc.Vector[qmc.Qubit]:
q = qmc.qubit_array(3, name="q")
# 既知の回路部分(非オラクル)
q[0] = qmc.h(q[0])
q[1] = qmc.h(q[1])
q[0], q[1] = qmc.cx(q[0], q[1])
# ループ外で 1 回オラクル呼び出し
q[0], q[1], q[2] = phase_oracle(q[0], q[1], q[2])
# 各ラウンドで既知ゲートと未知オラクルを混在
for i in qmc.range(rounds):
q[1] = qmc.ry(q[1], 0.3)
q[1], q[2] = qmc.cx(q[1], q[2])
q[0], q[1], q[2] = phase_oracle(q[0], q[1], q[2])
q[0], q[1], q[2] = mixing_oracle(q[0], q[1], q[2])
q[1], q[2] = qmc.cx(q[1], q[2])
return q
iterative_oracle_skeleton.draw(rounds=4, fold_loops=False)
oracle_est = iterative_oracle_skeleton.estimate_resources().simplify()
print("total gates:", oracle_est.gates.total)
assert str(oracle_est.gates.total) == "3*rounds + 3"
print("two-qubit gates:", oracle_est.gates.two_qubit)
assert str(oracle_est.gates.two_qubit) == "2*rounds + 1"
print("oracle_calls:", oracle_est.gates.oracle_calls)
assert {k: str(v) for k, v in oracle_est.gates.oracle_calls.items()} == {
"oracle": "rounds + 1",
"mixing": "rounds",
}
print("oracle_queries:", oracle_est.gates.oracle_queries)
assert {k: str(v) for k, v in oracle_est.gates.oracle_queries.items()} == {
"oracle": "2*rounds + 2",
"mixing": "rounds",
}total gates: 3*rounds + 3
two-qubit gates: 2*rounds + 1
oracle_calls: {'oracle': rounds + 1, 'mixing': rounds}
oracle_queries: {'oracle': 2*rounds + 2, 'mixing': rounds}
roundsに具体的な値を代入して、数値的なカウントを確認します:
oracle_est_4 = oracle_est.substitute(rounds=4)
print("oracle_calls (rounds=4):", oracle_est_4.gates.oracle_calls)
assert oracle_est_4.gates.oracle_calls == {"oracle": 5, "mixing": 4}
print("oracle_queries (rounds=4):", oracle_est_4.gates.oracle_queries)
assert oracle_est_4.gates.oracle_queries == {"oracle": 10, "mixing": 4}oracle_calls (rounds=4): {'oracle': 5, 'mixing': 4}
oracle_queries (rounds=4): {'oracle': 10, 'mixing': 4}
この例のように、オラクル内部が不明でも回路解析を進められます。既知部分は通常通りカウントされ、未知オラクル部分はoracle_calls(例: {'phase_oracle': rounds + 1, 'mixing_oracle': rounds})とoracle_queries(query_complexityで重み付け)として追跡されます。
このように完全な分解を実装する前にアルゴリズムレベルのコスト(量子ビット数、オラクルクエリ数等)を確認できます。
まとめ¶
ヘルパー
@qkernel:ある量子カーネルから別の量子カーネルを呼び出してコードを再利用できます。トランスパイラがインライン展開し、結果はフラットな回路になります。@composite_gate:量子カーネルに名前付きの識別子を与え、図で一つのゲートとして可視化します。@qkernelの上に@composite_gateデコレータを重ねて書きます。スタブゲート:
stub=TrueとResourceMetadataで、実装なしにトップダウン設計とリソース推定が可能です。est.gates.oracle_calls:オラクル内部が不明な状態でも、呼び出し回数を名前別の辞書として確認できます(シンボリックな回数もそのまま扱えます)。
制御ゲート(qmc.control)についてはチュートリアル04 — 制御ゲートを参照してください。