タグ: algorithm optimization variational
このチュートリアルでは、Qamomileの低レベル回路プリミティブを使って、QAOA (Quantum Approximate Optimization Algorithm) のパイプラインをステップごとに構築します。高レベルなQAOAConverterは使わずに、以下の手順で進めます:
小さなグラフでMaxCut問題を定義する。
スピン変数上のIsingモデルとして直接定式化する。
@qkernelを使ってQAOA回路をステップごとに記述する。古典オプティマイザで変分パラメータを最適化する。
結果をデコードして可視化する。
最後に、qamomile.circuit.algorithm.qaoa_stateが同じ回路を1つの関数呼び出しで提供することを示します。
# 最新のQamomileをpipからインストールします!
# !pip install qamomileMaxCut問題とは?¶
無向グラフが与えられたとき、MaxCut問題は頂点を2つの集合に分割し、2つの集合間を横切る辺の数を最大化する問題です。
MaxCutは本来、スピン変数で記述するのが自然な問題です。各頂点にスピンを割り当て、頂点がどちら側に属するかを表現します。辺が「カットされる」のはのときなので、カットされる辺数は
と書けます。
MaxCutやスピングラス基底状態探索、Isingモデルベンチマークといったスピン変数で自然に定義される問題は、スピン領域で記述するのが最もクリーンです。そこで本チュートリアルではQUBO/バイナリ変数への寄り道は挟まず、最初から最後までスピン変数で扱います。
グラフの作成¶
5頂点、6辺の小さなグラフを使います。全探索が可能な規模でありながら、自明でない構造を持っています。
import matplotlib.pyplot as plt
import networkx as nx
G = nx.Graph()
G.add_edges_from([(0, 1), (0, 2), (1, 2), (1, 3), (2, 3), (3, 4)])
num_nodes = G.number_of_nodes()
assert num_nodes == 5
assert G.number_of_edges() == 6
pos = nx.spring_layout(G, seed=42)
plt.figure(figsize=(5, 4))
nx.draw(
G,
pos,
with_labels=True,
node_color="white",
node_size=700,
edgecolors="black",
)
plt.title(f"Graph: {num_nodes} nodes, {G.number_of_edges()} edges")
plt.show()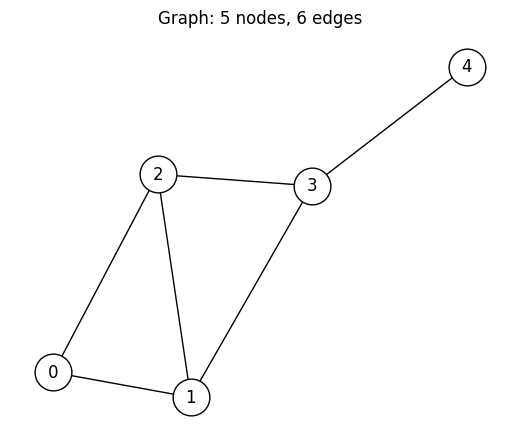
Ising定式化¶
を最大化することは、定数を除いて以下の反強磁性Isingハミルトニアンを最小化することと等価です:
一般のIsing形式と比較すると、重みなしMaxCutは以下の特徴を持ちます:
線形項なし: 全頂点について
一様な相互作用: 全辺について
BinaryModel.from_isingはIsing係数を直接受け取ります。QUBOを経由して変数型を変換する必要はありません。
from qamomile.optimization.binary_model import BinaryModel
ising_quad: dict[tuple[int, int], float] = {
tuple(sorted((i, j))): 1.0 for i, j in G.edges()
}
ising_linear: dict[int, float] = {}
# 重みつきMaxCutやスピングラスでは係数のスケールが揃っていないため、
# COBYLAなど勾配フリー最適化の収束を安定させる目的で
# `.normalize_by_abs_max()`を末尾に挟むとよい
spin_model = BinaryModel.from_ising(linear=ising_linear, quad=ising_quad)
print(f"Variable type: {spin_model.vartype}")
print(f"Linear terms (h_i): {spin_model.linear}")
print(f"Quadratic terms (J_ij): {spin_model.quad}")
print(f"Constant: {spin_model.constant}")
# スピン領域のモデルで、線形項は無し、各辺に 1 つの J_ij、定数項も無し。
assert spin_model.vartype.name == "SPIN"
assert spin_model.linear == {}
assert len(spin_model.quad) == G.number_of_edges()
assert spin_model.constant == 0.0Variable type: SPIN
Linear terms (h_i): {}
Quadratic terms (J_ij): {(0, 1): 1.0, (0, 2): 1.0, (1, 2): 1.0, (1, 3): 1.0, (2, 3): 1.0, (3, 4): 1.0}
Constant: 0.0
Note:
BinaryModelはQUBO向けのfrom_qubo()や高次版のfrom_hubo()も提供しており、割当問題や制約(ペナルティ項)を伴う問題のようにバイナリ領域で自然に定式化される問題に利用できます。QUBO/JijModelingベースのワークフローについてはQAOAによるグラフ分割を参照してください。
厳密解(全探索)¶
QAOAを実行する前に、すべての通りのスピン配置を試して最適な分割を求めておきます。QAOAの結果と比較するための基準になります。
import itertools
best_cut = 0
optimal_partitions: list[tuple[int, ...]] = []
for spins in itertools.product([+1, -1], repeat=num_nodes):
cut = sum(1 for i, j in G.edges() if spins[i] != spins[j])
if cut > best_cut:
best_cut = cut
optimal_partitions = [spins]
elif cut == best_cut:
optimal_partitions.append(spins)
print(f"Optimal MaxCut value: {best_cut}")
print(f"Number of optimal partitions: {len(optimal_partitions)}")
for part in optimal_partitions:
print(f" {part}")
# この固定された 5 ノード 6 辺のグラフでは MaxCut は 5、それを達成する
# スピン配置は大域反転 s -> -s で結ばれる 2 通りだけ。
assert best_cut == 5
assert len(optimal_partitions) == 2
for part in optimal_partitions:
assert tuple(-s for s in part) in optimal_partitionsOptimal MaxCut value: 5
Number of optimal partitions: 2
(1, -1, -1, 1, -1)
(-1, 1, 1, -1, 1)
QAOA回路: 基本的な考え方¶
QAOAのアンザッツはパラメータ付き量子状態を準備します:
ここで:
: 一様重ね合わせ(全量子ビットにHadamardゲート)
: コストユニタリ — Isingコストの場合、二次項はゲート、一次項はゲートに分解されます(ゲートの規約についてはステップ2–3を参照)
: ミキサーユニタリ — の場合、各量子ビットへのになります
: レイヤー数(アンザッツの深さ)
スピンと計算基底の対応は量子力学の標準的な規約, に従います。すなわち、測定結果0はスピン+1、測定結果1はスピン-1に対応します。
各コンポーネントを@qkernelとして実装していきます。
ステップ1: 一様重ね合わせ¶
全量子ビットにHadamardゲートを適用し、均等な重ね合わせ状態を作ります。
import qamomile.circuit as qmc
@qmc.qkernel
def superposition(n: qmc.UInt) -> qmc.Vector[qmc.Qubit]:
q = qmc.qubit_array(n, name="q")
for i in qmc.range(n):
q[i] = qmc.h(q[i])
return qステップ2: コスト層¶
コストユニタリを適用します。
Qamomileの回転ゲートはの因子を含む規約を使います: 、。と厳密に一致させるには角度をとすべきですが、は古典オプティマイザが自由に調整する変分パラメータであるため、この定数倍は最適なの値に吸収されます。したがって、(および)をそのまま渡します。
重みなしMaxCutではlinear引数は空ですが、そのまま引数として残しておきます。こうすることで、線形項を持つ重みつきMaxCutや一般のスピングラスハミルトニアンにそのまま流用できます。
@qmc.qkernel
def cost_layer(
quad: qmc.Dict[qmc.Tuple[qmc.UInt, qmc.UInt], qmc.Float],
linear: qmc.Dict[qmc.UInt, qmc.Float],
q: qmc.Vector[qmc.Qubit],
gamma: qmc.Float,
) -> qmc.Vector[qmc.Qubit]:
for (i, j), Jij in quad.items():
q[i], q[j] = qmc.rzz(q[i], q[j], angle=Jij * gamma)
for i, hi in linear.items():
q[i] = qmc.rz(q[i], angle=hi * gamma)
return qステップ3: ミキサー層¶
ミキサーユニタリを適用します()。なので、を実装するにはとします。
@qmc.qkernel
def mixer_layer(
q: qmc.Vector[qmc.Qubit],
beta: qmc.Float,
) -> qmc.Vector[qmc.Qubit]:
n = q.shape[0]
for i in qmc.range(n):
q[i] = qmc.rx(q[i], angle=2.0 * beta)
return qステップ4: 完全なQAOAアンザッツ¶
3つの要素を組み合わせます: 重ね合わせ → ラウンドのコスト層 + ミキサー層 → 測定。
@qmc.qkernel
def qaoa_ansatz(
p: qmc.UInt,
quad: qmc.Dict[qmc.Tuple[qmc.UInt, qmc.UInt], qmc.Float],
linear: qmc.Dict[qmc.UInt, qmc.Float],
n: qmc.UInt,
gammas: qmc.Vector[qmc.Float],
betas: qmc.Vector[qmc.Float],
) -> qmc.Vector[qmc.Bit]:
q = superposition(n)
for layer in qmc.range(p):
q = cost_layer(quad, linear, q, gammas[layer])
q = mixer_layer(q, betas[layer])
return qmc.measure(q)トランスパイルと最適化¶
カーネルをトランスパイルします。問題の構造(Ising係数、量子ビット数、レイヤー数)はバインドし、gammasとbetasはオプティマイザがチューニングするランタイムパラメータとして残します。
from qamomile.qiskit import QiskitTranspiler
transpiler = QiskitTranspiler()
p = 3 # QAOAレイヤー数
executable = transpiler.transpile(
qaoa_ansatz,
bindings={
"p": p,
"quad": spin_model.quad,
"linear": spin_model.linear,
"n": num_nodes,
},
parameters=["gammas", "betas"],
)scipy.optimize.minimizeのCOBYLA法を使います。各反復で回路をサンプリングし、平均エネルギーを評価します。
本チュートリアルでは再現性を確保するため、(i)AerSimulatorにseed_simulator=SEEDを渡してショットごとの擬似乱数サンプリングを決定的にし、(ii)NumPy乱数生成器も同じ値でシードして初期変分パラメータを固定し、(iii)スレッド間で乱数ドローが交錯しないようmax_parallel_threads=1に設定します。シングルスレッド化は若干の性能低下と引き換えに完全な再現性を得るための設定で、実運用コードでは省略するか、テスト/ドキュメントビルド時のみ有効化する形で構いません。
import os
import numpy as np
from qiskit_aer import AerSimulator
from scipy.optimize import minimize
SEED = 42
def make_seeded_backend() -> AerSimulator:
"""本チュートリアル用に決定的サンプリングを行うAerSimulatorを返す。"""
return AerSimulator(seed_simulator=SEED, max_parallel_threads=1)
executor = transpiler.executor(backend=make_seeded_backend())
docs_test_mode = os.environ.get("QAMOMILE_DOCS_TEST") == "1"
sample_shots = 256 if docs_test_mode else 2048
maxiter = 20 if docs_test_mode else 500
cost_history: list[float] = []
def cost_fn(params):
gammas = list(params[:p])
betas = list(params[p:])
result = executable.sample(
executor,
shots=sample_shots,
bindings={"gammas": gammas, "betas": betas},
).result()
decoded = spin_model.decode_from_sampleresult(result)
energy = decoded.energy_mean()
cost_history.append(energy)
return energy
rng = np.random.default_rng(SEED)
initial_params = rng.uniform(-np.pi / 2, np.pi / 2, 2 * p)
assert initial_params.shape == (2 * p,)
res = minimize(cost_fn, initial_params, method="COBYLA", options={"maxiter": maxiter})
print(f"Optimized cost: {res.fun:.4f}")
print(f"Optimal params: {[round(v, 4) for v in res.x]}")
assert len(cost_history) == res.nfev
assert len(res.x) == 2 * p
if docs_test_mode:
# docs テストモードでは COBYLA は maxiter の予算で打ち切られる。
assert res.nfev == maxiterOptimized cost: -2.8955
Optimal params: [np.float64(0.8595), np.float64(-0.3757), np.float64(1.4507), np.float64(0.4421), np.float64(-0.8647), np.float64(2.9358)]
plt.figure(figsize=(8, 4))
plt.plot(cost_history, color="#2696EB")
plt.xlabel("Iteration")
plt.ylabel("Cost (mean energy)")
plt.title("QAOA Optimization Progress")
plt.show()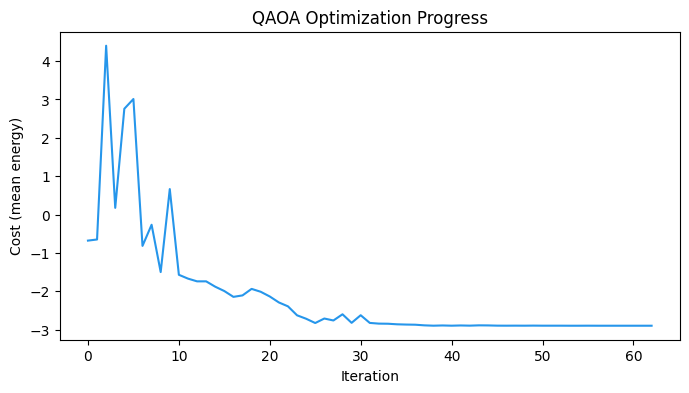
結果のデコードと分析¶
最適化されたパラメータで回路をサンプリングし、測定結果を解釈します。decode_from_sampleresultはスピン領域(+1 / -1)のサンプルを返すので、バイナリ変換を挟まずに直接カット辺数を数えられます。
gammas_opt = list(res.x[:p])
betas_opt = list(res.x[p:])
final_result = executable.sample(
executor,
shots=sample_shots,
bindings={"gammas": gammas_opt, "betas": betas_opt},
).result()
decoded = spin_model.decode_from_sampleresult(final_result)from collections import Counter
cut_distribution: Counter[int] = Counter()
best_qaoa_cut = 0
best_qaoa_sample = None
for sample, _energy, occ in zip(
decoded.samples, decoded.energy, decoded.num_occurrences
):
# sampleは{頂点インデックス: スピン値 (+1 or -1)}の辞書
spins = [sample[i] for i in range(num_nodes)]
cut = sum(1 for i, j in G.edges() if spins[i] != spins[j])
cut_distribution[cut] += occ
if cut > best_qaoa_cut:
best_qaoa_cut = cut
best_qaoa_sample = spins
print(f"Best QAOA cut: {best_qaoa_cut} (optimal: {best_cut})")
print(f"Best partition (spins): {best_qaoa_sample}")
# QAOA は全探索の最適値を超えられず、分布は最終サンプルの全ショットを
# 漏れなく数え上げているはず。
assert best_qaoa_cut <= best_cut
assert sum(cut_distribution.values()) == sample_shotsBest QAOA cut: 5 (optimal: 5)
Best partition (spins): [1, -1, -1, 1, -1]
cuts = sorted(cut_distribution.keys())
counts = [cut_distribution[c] for c in cuts]
plt.figure(figsize=(8, 4))
plt.bar([str(c) for c in cuts], counts, color="#2696EB")
plt.xlabel("Cut size")
plt.ylabel("Frequency")
plt.title("Distribution of MaxCut Values from QAOA")
plt.show()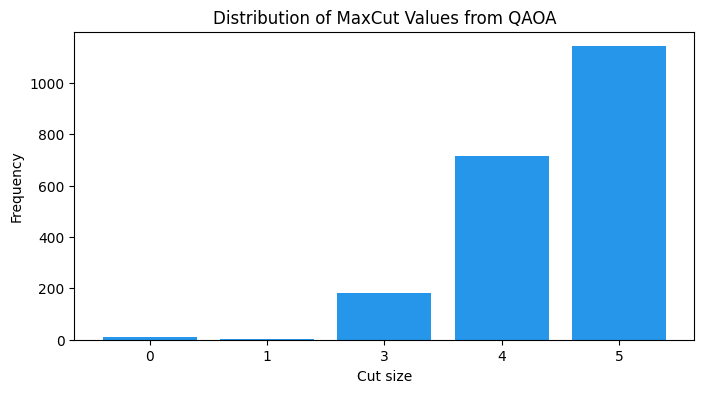
if best_qaoa_sample is not None:
color_map = [
"#FF6B6B" if best_qaoa_sample[i] == +1 else "#4ECDC4" for i in range(num_nodes)
]
plt.figure(figsize=(5, 4))
nx.draw(
G,
pos,
with_labels=True,
node_color=color_map,
node_size=700,
edgecolors="black",
)
plt.title(f"QAOA partition (cut = {best_qaoa_cut})")
plt.show()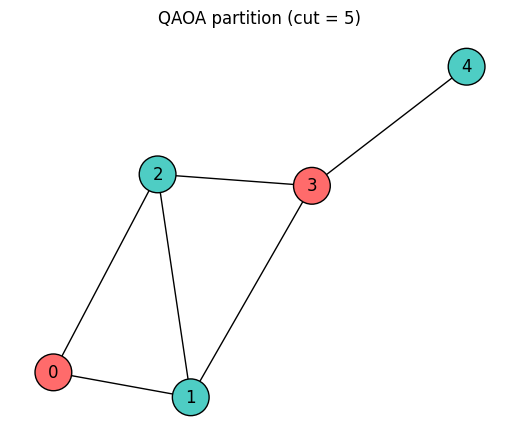
組み込みのqaoa_stateを使う¶
上で実装したすべて — 重ね合わせ、コスト層、ミキサー層、レイヤーのループ — はqamomile.circuit.algorithm.qaoa_stateとして既に提供されています。同じIsing係数(quad, linear)と変分パラメータ(gammas, betas)を受け取ります。
組み込み関数を使って同じ構造の回路が実装されていることを確認します。下記の各executorは同じseed_simulator=SEEDで初期化されているため、シードを揃えた条件下では回路が完全一致しているならばサンプル列も平均エネルギーも完全一致します。なお、有限ショットによる推定誤差(shot noise)はシードを揃えても消えるわけではなく、各回路に対して常に存在します。したがって両者の平均エネルギーに差分が残る場合は、shot noiseが原因ではなく手動版と組み込み版の回路が(ゲート順序やコンパイル過程の違いなどで)ビット単位では一致していないことを示します。
from qamomile.circuit.algorithm import qaoa_state
@qmc.qkernel
def qaoa_builtin(
p: qmc.UInt,
quad: qmc.Dict[qmc.Tuple[qmc.UInt, qmc.UInt], qmc.Float],
linear: qmc.Dict[qmc.UInt, qmc.Float],
n: qmc.UInt,
gammas: qmc.Vector[qmc.Float],
betas: qmc.Vector[qmc.Float],
) -> qmc.Vector[qmc.Bit]:
q = qaoa_state(p=p, quad=quad, linear=linear, n=n, gammas=gammas, betas=betas)
return qmc.measure(q)同じ最適化済みパラメータでトランスパイル・サンプリングします。
exe_builtin = transpiler.transpile(
qaoa_builtin,
bindings={
"p": p,
"quad": spin_model.quad,
"linear": spin_model.linear,
"n": num_nodes,
},
parameters=["gammas", "betas"],
)
executor_manual = transpiler.executor(backend=make_seeded_backend())
executor_builtin = transpiler.executor(backend=make_seeded_backend())
result_manual = executable.sample(
executor_manual,
shots=sample_shots,
bindings={"gammas": gammas_opt, "betas": betas_opt},
).result()
result_builtin = exe_builtin.sample(
executor_builtin,
shots=sample_shots,
bindings={"gammas": gammas_opt, "betas": betas_opt},
).result()
decoded_manual = spin_model.decode_from_sampleresult(result_manual)
decoded_builtin = spin_model.decode_from_sampleresult(result_builtin)
print(f"Manual mean energy: {decoded_manual.energy_mean():.4f}")
print(f"Built-in mean energy: {decoded_builtin.energy_mean():.4f}")
# 同じシード + ビット単位で同一の回路 ⇒ サンプル列も平均も完全一致するはず。
# 差分が出る場合は手動版と組み込み版がビット単位で異なる回路を emit したという
# サイン (ゲート順序やコンパイル経路の差) であり、shot noise の残差ではない。
assert decoded_manual.energy_mean() == decoded_builtin.energy_mean()Manual mean energy: -2.8955
Built-in mean energy: -2.8955
まとめ¶
このチュートリアルでは:
MaxCut問題を定義し、QUBO/バイナリ変数を経由せずに直接スピン変数上のIsingハミルトニアンとして記述しました。
BinaryModel.from_isingでスピン領域のBinaryModelを構築しました。QAOA回路の全コンポーネント — 重ね合わせ、コスト層、ミキサー層、完全なアンザッツ — を
@qkernelとして実装しました。古典最適化ループを実行し、スピン領域のまま結果をデコードしました。
qamomile.circuit.algorithm.qaoa_stateが同じ回路を1つの関数呼び出しで提供することを確認しました。
この「スピンから始める」レシピは、スピングラス基底状態探索、重みつきMaxCut、Sherrington–Kirkpatrickモデルといった任意のIsing型問題にそのまま適用できます。とをBinaryModel.from_isingに渡し、上で作成した回路コンポーネントを再利用するだけです。
次のステップ:
バイナリ変数で自然に定式化される問題や、制約(ペナルティ項)が必要な問題については、JijModelingと高レベルの
QAOAConverterを使うQAOAによるグラフ分割を参照してください。