タグ: algorithm optimization variational
このチュートリアルでは、QamomileのPCEConverterを用いて、Pauli Correlation Encoding(PCE)でMaxCut問題を解いてみます。PCEは個のスピン変数を、量子ビットのレジスタ上の体Pauli相関演算子の期待値に写像します。これにより、変数1つあたり1量子ビットを使うQAOA定式化よりも必要な量子ビット数を減らします。
本チュートリアルでは、20頂点のMaxCutインスタンスをで3量子ビットに符号化します。PCEConverterで符号化を構築し、ハードウェア効率の良い@qkernelアンザッツで各相関演算子の期待値を推定します。次にscipy.optimize.minimizeでアンザッツを最適化し、最後にconverter.decodeで最終的な期待値をデコードして、全探索によるベースラインと比較します。
# 最新のQamomileをpipからインストールします!
# !pip install qamomileimport os
import matplotlib.pyplot as plt
import networkx as nx
import numpy as np
from scipy.optimize import minimize
import qamomile.circuit as qmc
from qamomile.circuit.algorithm.basic import (
cx_entangling_layer,
ry_layer,
rz_layer,
)
from qamomile.optimization.binary_model import BinaryModel, BinarySampleSet
from qamomile.optimization.pce import PCEConverter
from qamomile.qiskit import QiskitTranspiler問題設定¶
MaxCut問題とは?¶
無向グラフが与えられたとき、MaxCut問題は頂点を2つの集合とに分割し、2つの集合間の辺の数を最大化する問題です。各頂点にスピン変数を割り当てます。なら頂点はに入り、ならに入ります。カット値は次のように書けます。
各辺は両端のスピンが反対側にあるとき()に1、同じ側にあるとき()に0を寄与します。したがってカットを最大化することは、Isingエネルギー
を最小化することと等価です。これは、各辺で、定数項を持つIsingモデルです。PCEはこのスピン形式を直接扱えるため、二値変数からの追加変換は不要です。
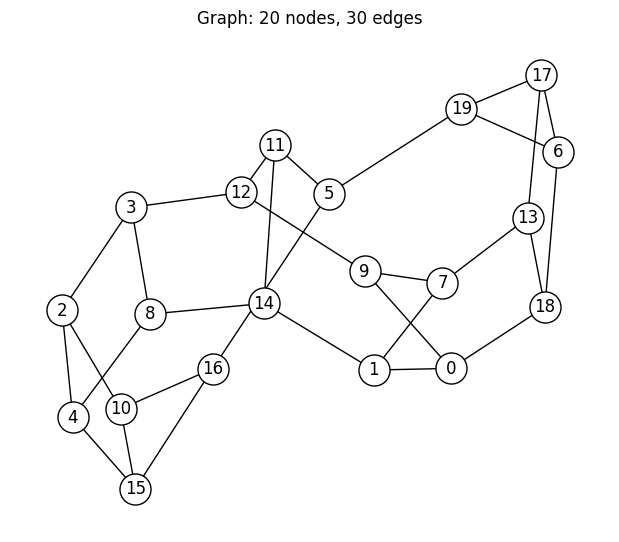
グラフの作成¶
20頂点の3-正則ランダムグラフを使用します。各頂点はちょうど3つの隣接頂点を持つので、辺となります。3-正則グラフのMaxCutはPCE論文のベンチマークです。このインスタンスは、全探索によって真の最適値を計算できる規模です。
nx.random_regular_graphは非連結なグラフを生成することがあるため、連結なグラフが得られるまでseedを増やします。これにより、複数の独立した成分ではなく、1つの分割問題を扱います。
seed = 42
while True:
G = nx.random_regular_graph(3, 20, seed=seed)
if nx.is_connected(G):
break
seed += 1
print(f"Using seed = {seed} (smallest seed >= 42 producing a connected graph)")
num_nodes = G.number_of_nodes()
num_edges = G.number_of_edges()
pos = nx.spring_layout(G, seed=42)
plt.figure(figsize=(6, 5))
nx.draw(
G,
pos,
with_labels=True,
node_color="white",
node_size=500,
edgecolors="black",
)
plt.title(f"Graph: {num_nodes} nodes, {num_edges} edges")
plt.show()Using seed = 42 (smallest seed >= 42 producing a connected graph)
アルゴリズム¶
PCEはSciorilliらSciorilli et al., 2024が提案した、少ない量子ビット数で組合せ最適化を扱う手法です。標準的なQAOAは変数ごとに1量子ビットを使います。PCEは変数の問題に対し量子ビットを使います。
PCE符号化¶
PCEは相関演算子の次数を選び、スピン変数をそれぞれ別個の体Pauli相関演算子に割り当てます。各はから選んだ恒等演算子でない個のPauli演算子のテンソル積で、量子ビットのうち個に作用します。量子ビット上に存在するこのような相関演算子は個なので、は次を満たす最小の整数として選びます。
ならば、ならばとなります。こののインスタンスでは、で量子ビットが必要です。これはを満たす最小の整数です。変数から相関演算子への割り当ては決定的に決まります。量子ビット上の体Pauli文字列の固定列挙を1つ用意し、その先頭個を変数へ割り当てます。
コスト関数¶
パラメータ付きアンザッツ状態が与えられたとき、PCEは離散的なスピン目的関数
を、各スピンをtanh緩和した相関演算子期待値に置き換え、さらに緩和変数の早い飽和を抑える4次の正則化項を加えることで、滑らかな代理損失関数へ変換します。tanh写像によりは開区間に入り、この領域では符号丸めで候補ビット列を復元できます。
データ項は接続された各ペアでとを逆符号へ引き寄せます。つまりが負になる方向へ働きます。正則化項は大きな緩和値にペナルティーを与えてこの圧力と釣り合いを取ります。これにより、オプティマイザを領域の滑らかな内部に保ち、劣ったビット列への早期収束を抑えます。
この損失には3つのハイパーパラメータ(tanhの鋭さ)、(正則化項の強さ)、(全体スケール)が含まれます。これらの値はオプティマイザの収束と最終的なビット列の品質に影響します。本チュートリアルで用いる具体的な値は元論文に従い、Step 5: 変分パラメータの最適化で設定します。
MaxCutに限れば、スピンモデルは、各辺でなので、データ項は隣接するが逆符号となるとき最小になります。
Qamomileでの実装¶
Step 1: BinaryModelとPCEConverterの構築¶
問題設定で導出したIsing形式をBinaryModel.from_isingで構築します。係数は、各辺で、定数項です。得られたスピンモデルと相関演算子の次数をPCEConverterに渡すと、コンバータが必要な量子ビット数を決めます。このスケーリングではスピンモデルのエネルギーがカット値の符号反転に等しくなります。カットが大きいほどエネルギーが低くなります。
quad = {(i, j): 0.5 for i, j in G.edges()}
ising_model = BinaryModel.from_ising(
linear={},
quad=quad,
constant=-num_edges / 2,
)
converter = PCEConverter(ising_model, correlator_order=2)
spin_model = converter.spin_model
print(f"Number of variables : {spin_model.num_bits}")
print(f"PCE qubit count : {converter.num_qubits}")
print(f"Correlator order (k) : {converter.correlator_order}")
print(f"Compression ratio : {spin_model.num_bits / converter.num_qubits:.1f}x")
assert spin_model.num_bits == 20
assert converter.num_qubits == 3
assert converter.correlator_order == 2Number of variables : 20
PCE qubit count : 3
Correlator order (k) : 2
Compression ratio : 6.7x
Step 2: 変数ごとのPauliオブザーバブルを確認する¶
get_encoded_pauli_list()は変数ごとに1つのHamiltonianを返します。各Hamiltonianは係数1の体Pauli文字列をちょうど1つ含みます。これらがアルゴリズムで言及したオブザーバブルです。最適化ループはアンザッツの量子カーネル内のqmc.expvalで、それらの期待値を推定します。
observables = converter.get_encoded_pauli_list()
print(f"Total observables : {len(observables)}")
for i, P_i in enumerate(observables):
print(f" P_{i:2d}: {P_i}")
assert len(observables) == spin_model.num_bits
# 各オブザーバブルは係数1のk体Pauli文字列1つです。
for P_i in observables:
coeffs = list(P_i.terms.values())
assert len(coeffs) == 1 and abs(coeffs[0] - 1.0) < 1e-12Total observables : 20
P_ 0: Hamiltonian((X0, X1): 1.0)
P_ 1: Hamiltonian((X0, Y1): 1.0)
P_ 2: Hamiltonian((X0, Z1): 1.0)
P_ 3: Hamiltonian((Y0, X1): 1.0)
P_ 4: Hamiltonian((Y0, Y1): 1.0)
P_ 5: Hamiltonian((Y0, Z1): 1.0)
P_ 6: Hamiltonian((Z0, X1): 1.0)
P_ 7: Hamiltonian((Z0, Y1): 1.0)
P_ 8: Hamiltonian((Z0, Z1): 1.0)
P_ 9: Hamiltonian((X0, X2): 1.0)
P_10: Hamiltonian((X0, Y2): 1.0)
P_11: Hamiltonian((X0, Z2): 1.0)
P_12: Hamiltonian((Y0, X2): 1.0)
P_13: Hamiltonian((Y0, Y2): 1.0)
P_14: Hamiltonian((Y0, Z2): 1.0)
P_15: Hamiltonian((Z0, X2): 1.0)
P_16: Hamiltonian((Z0, Y2): 1.0)
P_17: Hamiltonian((Z0, Z2): 1.0)
P_18: Hamiltonian((X1, X2): 1.0)
P_19: Hamiltonian((X1, Y2): 1.0)
Step 3: アンザッツの定義¶
PCEでは回路を自由に選べます。原論文ではHardware-efficient ansatzを使います。これは単一量子ビット回転と2量子ビットのエンタングリングゲートを交互に積み重ねる構成です。本チュートリアルではqamomile.circuit.algorithm.basicが提供する事前定義のレイヤ(ry_layer、rz_layer、cx_entangling_layer)をdepth回スタックして使い、合計で個の変分角度を持たせます。量子カーネルはを返します。Pはトランスパイル時のbindingsで固定されるオブザーバブルなので、同じ量子カーネルをごとに1回ずつトランスパイルします。
@qmc.qkernel
def pce_ansatz(
n: qmc.UInt,
depth: qmc.UInt,
thetas: qmc.Vector[qmc.Float],
P: qmc.Observable,
) -> qmc.Float:
q = qmc.qubit_array(n, name="q")
for i in qmc.range(n):
q[i] = qmc.h(q[i])
for d in qmc.range(depth):
offset = d * 2 * n
q = ry_layer(q, thetas, offset) # type: ignore[arg-type]
q = rz_layer(q, thetas, offset + n) # type: ignore[arg-type,operator]
q = cx_entangling_layer(q)
return qmc.expval(q, P)アンザッツの構造を具体的に示すため、量子ビット、depth = 1(レイヤー数1)の回路図を示します。Pは最初の符号化オブザーバブルに固定し、thetasはランタイムパラメータとして残します。
pce_ansatz.draw(n=3, depth=1, P=observables[0], fold_loops=False)
Step 4: オブザーバブルごとに1つのExecutableProgramへとトランスパイルする¶
各はトランスパイル時に固定する必要があるため、オブザーバブルごとに1回トランスパイルし、得られたExecutableProgramをリストに保存します。各transpiler.transpile(...)は、トランスパイル済みのバックエンド回路とランタイムパラメータの再バインドに必要なメタデータをまとめたExecutableProgramを返します。トランスパイル時のbindingsは構造的な入力(n、depth、P)を固定し、parameters=["thetas"]は変分角度をオプティマイザが呼び出しのたびに変更できるランタイムパラメータとして残します。
transpiler = QiskitTranspiler()
n = converter.num_qubits
depth = 3
num_thetas = 2 * n * depth
executables = [
transpiler.transpile(
pce_ansatz,
bindings={"n": n, "depth": depth, "P": P_i},
parameters=["thetas"],
)
for P_i in observables
]
print(f"Executables cached : {len(executables)}")
print(f"Variational params : {num_thetas} (= 2 * n * depth)")
assert len(executables) == len(observables)
assert num_thetas == 2 * n * depthExecutables cached : 20
Variational params : 18 (= 2 * n * depth)
Step 5: 変分パラメータの最適化¶
古典ループは現在のthetasで全オブザーバブルに対しを推定し、得られた値をアルゴリズムのtanh緩和損失(データ項+正則化項)に代入し、scipy.optimize.minimizeに角度を更新させます。
損失の3つのハイパーパラメータは元論文に従って次のように設定します。
(tanhの鋭さ): と設定します。はグラフのノード数、は相関演算子の次数で、本チュートリアル(20ノード、)ではとなります。
(正則化項の強さ): 論文においてチューニング済みの固定値を使います。
(全体スケール): Edwards-ErdősのMaxCut下界を使用します。
executor = transpiler.executor()
docs_test_mode = os.environ.get("QAMOMILE_DOCS_TEST") == "1"
maxiter = 10 if docs_test_mode else 100
# https://doi.org/10.48550/arXiv.2401.09421 のハイパーパラメータ:
# alpha = N^(k/2) (N = ノード数、k = PCEの相関演算子の次数)
# beta = 1/2 (正則化項の強さ)
# nu = |E| / 2 + (N - 1) / 4 (MaxCutに対するEdwards-Erdős下界)
N = spin_model.num_bits
k = converter.correlator_order
alpha = float(N ** (k / 2))
beta = 0.5
nu = num_edges / 2 + (N - 1) / 4
print(f"alpha = {alpha}, beta = {beta}, nu = {nu}")
cost_history: list[float] = []
def measure_expectations(thetas: list[float]) -> list[float]:
return [
exe.run(executor, bindings={"thetas": thetas}).result() for exe in executables
]
def loss(params: np.ndarray) -> float:
thetas = list(params)
expvals = measure_expectations(thetas)
relaxed = [np.tanh(alpha * e) for e in expvals]
# データ項: スピン目的関数の滑らかな代理損失関数。
L_data = 0.0
for (i, j), J_ij in spin_model.quad.items():
L_data += J_ij * relaxed[i] * relaxed[j]
for i, h_i in spin_model.linear.items():
L_data += h_i * relaxed[i]
# 正則化項: beta * nu * [(1/N) sum tanh^2(alpha <P_i>)]^2.
mean_sq = sum(r**2 for r in relaxed) / N
L_reg = beta * nu * mean_sq**2
L_total = L_data + L_reg
cost_history.append(L_total)
return L_total
rng = np.random.default_rng(42)
initial_params = rng.uniform(-np.pi, np.pi, num_thetas)
res = minimize(loss, initial_params, method="BFGS", options={"maxiter": maxiter})
print(f"Final loss: {res.fun:+.4f}")alpha = 20.0, beta = 0.5, nu = 19.75
Final loss: -3.4750
plt.figure(figsize=(8, 4))
plt.plot(cost_history, color="#2696EB")
plt.xlabel("Iteration")
plt.ylabel("Loss")
plt.title("PCE Optimization Progress")
plt.show()
Step 6: 最適化済みの期待値をデコードする¶
PCEConverter.decode(expectations)は変数ごとの期待値を受け取り、それぞれを符号丸めしてスピンに変換し、入力モデルと同じvartypeで1サンプルのBinarySampleSetを返します。ここではising_modelをBinaryModel.from_isingで構築したため、vartypeはSPINです。出力されるエネルギーは問題設定で設定した規約(エネルギー=)に従うので、デコード後のエネルギーはカット値の負の値です。
final_expectations = measure_expectations(list(res.x))
sampleset = converter.decode(final_expectations)
# ``PCEConverter`` を ``BinaryModel`` (上の ``ising_model``) から構築したので、
# ``decode`` は ``BinarySampleSet`` を返す。型上は ``BinarySampleSet | SampleSet``
# の Union (converter は OMMX ``Instance`` も受け入れるため) なので、ここで
# narrow して下の ``.vartype`` / ``.energy`` / ``.samples`` を通す。
assert isinstance(sampleset, BinarySampleSet)
print("Final per-variable expectations:")
for i, e in enumerate(final_expectations):
print(f" <P_{i:2d}> = {e:+.4f}")
print()
print(f"Decoded vartype : {sampleset.vartype}")
print(f"Decoded energy : {sampleset.energy[0]:+.4f}")Final per-variable expectations:
<P_ 0> = -0.0848
<P_ 1> = +0.0894
<P_ 2> = +0.3133
<P_ 3> = -0.0118
<P_ 4> = -0.0372
<P_ 5> = -0.2572
<P_ 6> = -0.0396
<P_ 7> = -0.0292
<P_ 8> = +0.0418
<P_ 9> = +0.2510
<P_10> = -0.0481
<P_11> = +0.2302
<P_12> = -0.2536
<P_13> = -0.0224
<P_14> = -0.0883
<P_15> = +0.0071
<P_16> = +0.0680
<P_17> = +0.0666
<P_18> = +0.3815
<P_19> = +0.0159
Decoded vartype : SPIN
Decoded energy : -26.0000
結果¶
古典ベースライン(全探索)¶
通りすべてのスピン配置を列挙すると、約100万個の割り当てを調べることになります。単純なPythonループでは多すぎますが、ベクトル化したNumPyを1回通すだけなら短時間で完了します。各配置は整数でラベル付けし、ビットが0なら、1ならと対応付けたうえで、となる辺の数を数えます。これで次のサブセクションでPCEの結果と比較するための真の最適値が得られます。
assignments = np.arange(2**num_nodes, dtype=np.int64)
cuts = np.zeros(2**num_nodes, dtype=np.int32)
for i, j in G.edges():
s_i = 1 - 2 * ((assignments >> i) & 1) # bit 0 → +1, bit 1 → -1
s_j = 1 - 2 * ((assignments >> j) & 1)
cuts += (s_i != s_j).astype(np.int32)
best_cut = int(cuts.max())
optimal_assignment_ints = np.flatnonzero(cuts == best_cut)
print(f"Optimal MaxCut value : {best_cut}")
print(f"Number of optimal partitions : {len(optimal_assignment_ints)}")
# グラフseedは固定なので、全探索の最適値は決定的に決まります。
assert best_cut == 26Optimal MaxCut value : 26
Number of optimal partitions : 12
デコードと結果の分析¶
ベストカット¶
デコードされたスピン割り当てをグラフ分割に変換し、古典ベースライン(全探索)の全探索による厳密解と比較します。整合性チェックとして、カット値はStep 6: 最適化済みの期待値をデコードするで出力したスピンエネルギーの-1倍と一致するはずです。
sample = sampleset.samples[0]
spins = [sample[i] for i in range(num_nodes)]
pce_cut = sum(1 for i, j in G.edges() if spins[i] != spins[j])
print(f"PCE spin assignment : {spins}")
print(f"PCE cut value : {pce_cut}")
print(f"Brute-force optimum : {best_cut}")
print(f"Approximation ratio : {pce_cut / best_cut:.3f}")PCE spin assignment : [-1, 1, 1, -1, -1, -1, -1, -1, 1, 1, -1, 1, -1, -1, -1, 1, 1, 1, 1, 1]
PCE cut value : 26
Brute-force optimum : 26
Approximation ratio : 1.000
解の可視化¶
各ノードを所属するパーティション側で色分けします。色が異なるノード同士は、カットの反対側に位置します。
color_map = ["#FF6B6B" if spins[i] == 1 else "#4ECDC4" for i in range(num_nodes)]
plt.figure(figsize=(6, 5))
nx.draw(
G,
pos,
with_labels=True,
node_color=color_map,
node_size=500,
edgecolors="black",
)
plt.title(f"PCE partition (cut = {pce_cut} / optimum = {best_cut})")
plt.show()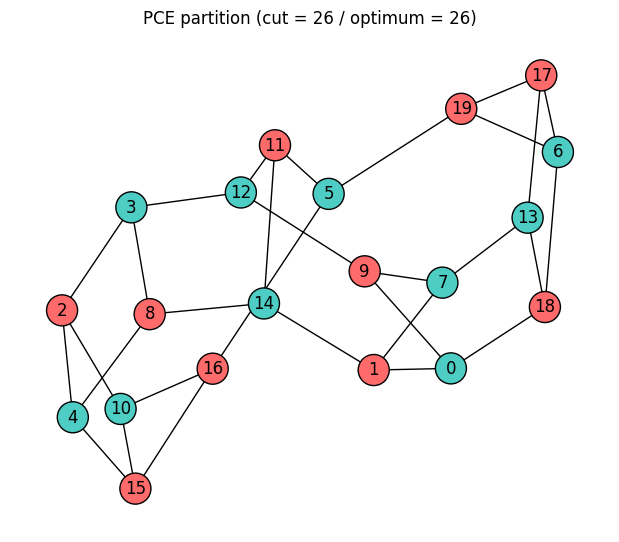
まとめ¶
本チュートリアルでは、20ノードの3-正則グラフ上のMaxCut問題をPauli Correlation Encoding(PCE)でエンコードし、相関演算子の符号化からデコードによるスピン割り当ての復元までを行う、Qamomileのワークフロー全体を扱いました。
量子ビットのリソース効率: PCEは20個のスピン変数を、2体のPauli相関演算子によってわずか3量子ビットで表現しました。変数あたり1量子ビットを使うQAOA符号化と比べて約7倍の削減です。
代理損失関数による最適化: 変分ループでは、エネルギーを直接最小化するのではなく、tanh緩和による代理損失関数を最小化しました。デコードした割り当ては全探索の最適値と一致しました。
Qamomileによるエンドツーエンドの流れ:
PCEConverterが与えられた古典変数を符号化し、対応するオブザーバブルをget_encoded_pauli_listで取得しました。@qkernelで実装されたHardware-efficient ansatzとqmc.expvalを利用して各相関演算子の期待値を推定し、QiskitTranspilerがExecutableProgramを生成して、オプティマイザを使ってパラメータを調整しました。最後にconverter.decodeを用いて調整後のパラメータを使って得られた期待値を符号丸めして対応する古典変数を取り出しました。
今回のPCEConverterのワークフローは、量子ビット数がボトルネックになる任意のQUBO/Ising組合せ最適化問題に応用できます。自分のBinaryModelを差し替えれば、上記の符号化・トランスパイル・デコードの手順をそのまま再利用できます。
- Sciorilli, M., Borges, L., Patti, T. L., García-Martín, D., Camilo, G., Anandkumar, A., & Aolita, L. (2024). Towards large-scale quantum optimization solvers with few qubits. 10.48550/ARXIV.2401.09421